High level overview and concepts
This a completely asynchronous real-time incremental speech to text API, oriented towards conversations with multiple speakers.
What does that mean?
Real-time
This API is optimized for real-time speech decoding. It is not meant to be used for batch file transcription. We offer more appropriate, dedicated APIs for batch processing. Contact our commercial support.
Conversation oriented
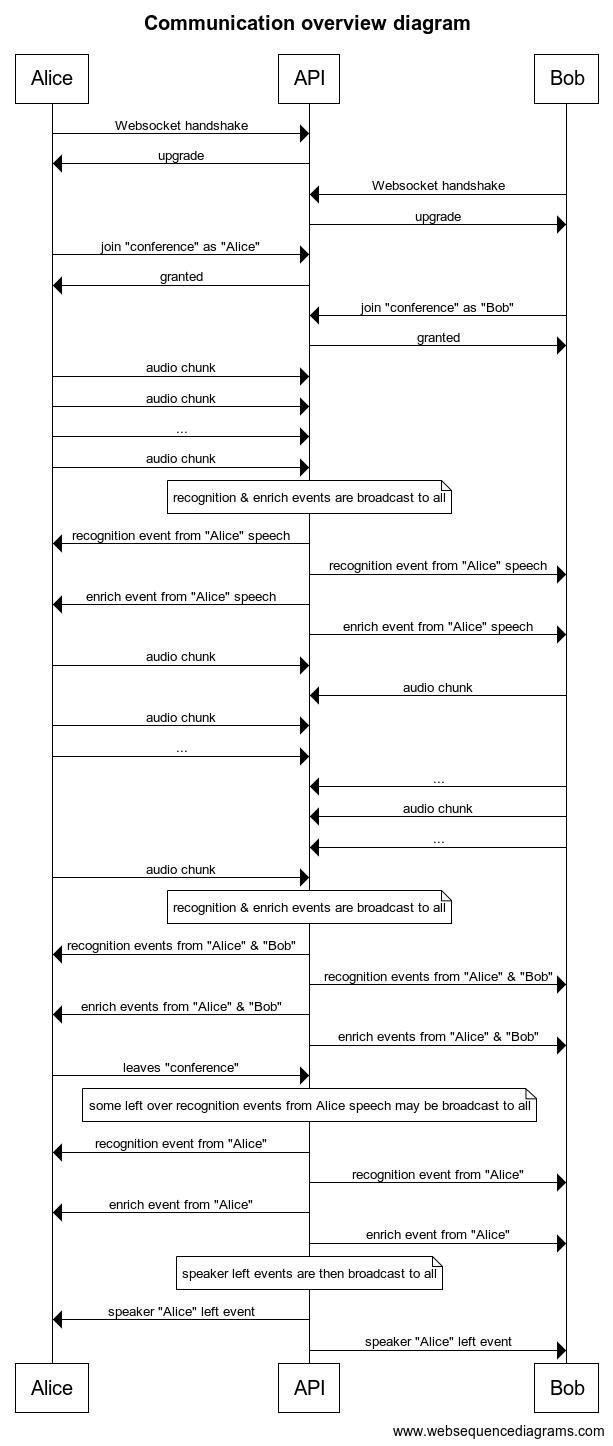
In this API, everything happens within a conversation.
The first thing a client does when connecting to the API is joining a conversation. Conversations are private to your organization, and any number of participant clients can join a given conversation, as long as they have the right credentials and they know its identifier.
Each participant is identified by a speaker string of its choice. A participant can be active, that is, it will both stream audio data to the conversation and receive recognition events, or it can join as an observer, in read-only mode, to just receive the recognition events.
Each recognition event bears the name of the speaker whose audio it transcribes.
Asynchronous and incremental
This is not a request-response API. You open a long lived websocket connection, and if you are an active participant, you stream audio. In parallel, you receive recognition events.
The speech recognition starts as soon as it receives the first bytes and progresses in parallel as new audio chunks come in, broadcasting recognition and enrich events to all participants along the way. That behavior is particularly well suited for real-time speech recognition, as you don't have to wait for the end of the conversation (for example, a phone call) to start decoding: you get the transcription of the conversation in realtime, as it happens.
That approach is also very efficient for transcribing big files, because you don't need to send them as one big chunk. In the opposite, you should send files chunk by chunk (64KB maximum per chunk) as you read them from disk, without waiting for an answer, so that the decoding starts while uploading.
As there is no synchronization/correlation between the up stream (audio) and down stream (recognition and enrich events), clients have to be able to write and listen in parallel, either by using threads (fibers, coroutines, etc…) or using evented I/O (aka asyncIO).
This is how it would look like (pseudo-code):
func listen(websocket, speaker) {
while event = websocket.read_message() {
if event is SpeakerLeft(speaker) {
break;
}
// process events
…
…
}
}
func stream_file(file_handle, websocket, speaker, topic) {
while chunk = file_handle.read(8192) {
message = new AudioMessage(chunk, topic);
websocket.send_message(message);
}
message = new LeaveMessage(speaker, topic);
websocket.send_message(message);
}
func main(){
websocket = new WebSocket("wss://…");
speaker = "…";
topic = "…";
websocket.send_message(JoinMessage(speaker, topic));
file_handle = new File("…");
streamer = spawn(stream_file, websocket, speaker, topic);
listen(websocket, speaker);
join(streamer)
}Recognition events
The transcription unit on which recognition events are based is the segment. A segment correspond to a single utterance of speech.
There are two kinds of recognition events: interim result events, and final segment events.
- Interim result events are emitted as soon a a new segment starts, and represents the current state (fast estimation) of the decoding, until an End of Segment (EoS) is detected.
- Then, a final segment event is published, that gives the final, definitive transcript of the speech segment.
And so on for all segments.
To make life easier, all recognition events related to the same utterance bear the same utterance ID.
Enrich events
During the conversation, various NLP processors are run according to your subscription. They emit annotation events that interpret and enrich the transcript. Those annotations are anchored on the transcript timeline, so that:
- they can also apply to non-speech sound,
- you can rewrite the transcript according to the interpretation in order to improve readability, or to hide sensitive information.
Another kind of enrich event is used to link several annotations together when they describe the same real word entity or concept. For example, to link a credit card number with the expiration date of the actual credit card.
Other events
When a participant leaves the conversation, all participants are notified.
Recognition parameters
When an active speaker joins a conversation, they can set the recognition parameters of the ASR engine used to transcribe their speech.
Those parameters are:
model: (required) the ASR model to be used, that depends on the language of the speaker, but also on the application domain for special business needs. See the complete list. There is no default, you must provide it.interim_resultsflag: you can disable interim result events by setting this flag tofalse. Default istrue.rescoringflag: you can disable the automatic rescoring of the final segment events on the bigger language model by setting this flag tofalse. If you don't know what it is, let in ontrue(default).origin: as all recognition events (and words within them) are timestamped, you can specify the time at which the audio starts as a Unix timestamp is milliseconds. This origin can be in the past if you are streaming recorded audio. All event timings will be based on this origin.