Real-time Stream API for voicebots
Stream for voicebots, or Stream Human to Bots, or Stream H2B is a set of API enabling clients to build interaction between a human end-user and a bot, for example to create Interactive Voice Response (IVR) on the phone, or a voicebot within an app.
Two protocols are available to access this API's features: MRCP and WebSocket.
These protocols mainly differ (aside from the Application Layer of course) by the way client is authenticated, authorized, and by the nature of the payload (XML for MRCP and JSON for WebSocket). Beyond this both offer the same set of features.
Overview
TL;DR
- The client opens a new session, specifying session attributes that will then appear on invoices. Session attributes are useful for the client's accounting purposes.
- Once a session is opened, the client can start streaming audio. No transcription will occur yet (and hence, no fees!).
- While streaming, the client can send different commands (in the same connection) to the server.
- The client can also close the session. It must stop streaming then.
Detailed overview
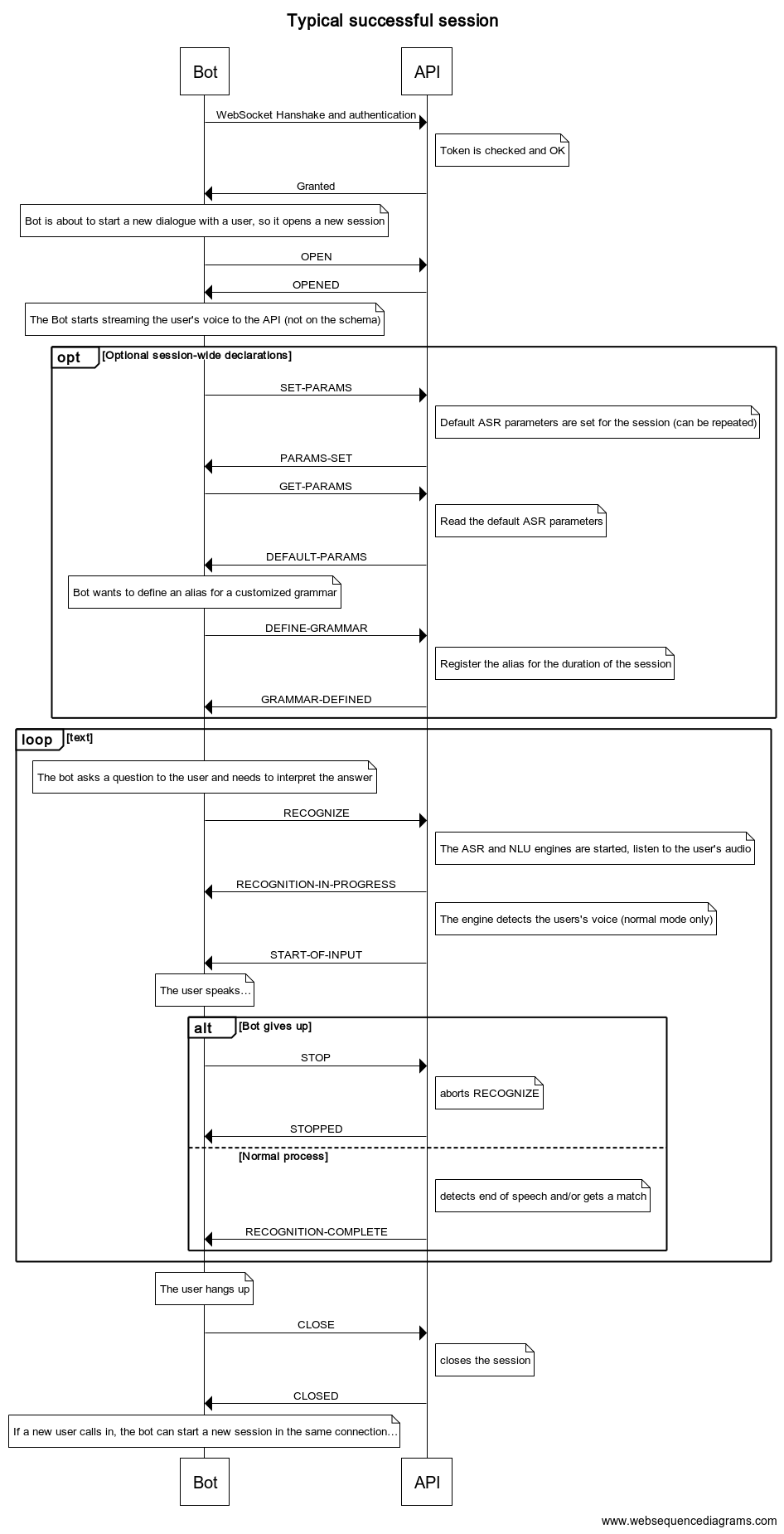
Once the client is granted access, it can run several successive sessions without disconnecting and reconnecting.
A session is a context to which attributes (called "session" attributes) can be attached and a unit of work that scopes "global" or defaults recognition parameters the client may set and in which recognition requests are issued. In general, we recommend that a session matches a human-bot interview or "conversation" (e.g. a phone call): the session is started at the beginning of the call and stopped at hang up.
Contrary to the conversation based API, only one speaker audio is streaming during a session and the ASR doesn't run continuously. The ASR+NLU is started by a recognition request when the client needs it, and it stops when the expected information is found or when some timer expires. The client describes the information it expects by one or more grammars. A grammar is a kind of preset identified by an URI that will set up both our ASR and NLU engines for the task. Some of these presets can be further customized by the client by passing parameters to them in a "query" string.
The client can issue several recognition requests during a session, but at any given time, at most one request may be active. You cannot have concurrent recognition requests running in parallel. If you want to try several possible interpretations at the same time, you would use one request with several grammars.
The server respond to each message with a success or error message.
Any audio packet sent outside a session is ignored instead of raising an error because in practice the client won't always be able to perfectly synchronize the audio and the commands (this is a real life observation). Indeed, a client typical architecture involves different threads or subsystems for bot orchestration and audio streaming.
Besides the responses to the requests, the server emits some events as the recognition process progresses: START-OF-INPUT and RECOGNITION-COMPLETE.
Getting started
In order to ease use of the WebSocket protocol, we provide a Python SDK.
For both MRCP and WebSocket, you'll find more documentation on what requests are made of in the input section while the output section describes what responses look like.
A complete list of supported grammars is available, with information about which ones to use depending on your use cases.
Dedicated information for each protocol can be found within their own section: