Input protocol
This page describes what requests from client to server look like, and what clients can parameter.
Commands
Commands are request methods from the client to the server. They allow the former to set up parameters to prepare ASR, as well as requesting transcription itself.
SET-PARAMS
Allow client to define recognition parameters for the session's duration, or until another SET-PARAMS command replaces them.
GET-PARAMS
Asks for current session parameters.
DEFINE-GRAMMAR
Define a grammar and its options, and name it, in order to use it later on during recognition. For example a spelling digits grammar with a length of 7 characters.
The definition is valid for the duration of the session.
Only builtin grammars are supported, not custom grammars sent as SRGS XML.
RECOGNIZE
Client requests server to start speech recognition. Multiple active grammars are supported without weights.
The command can temporarily override any parameter previously set with SET-PARAMS. the recognition parameters (including the chosen grammars) define precisely how and when the recognition stops.
The success response to this command is a RECOGNITION-IN-PROGRESS event, which includes a unique request-id for the session's duration.
STOP
Client tells server to stop active ongoing RECOGNIZE, if any exists.
For example if user hangs up, you'll want to send this command because there is no more point in transcribing anymore.
START-INPUT-TIMERS
In case of barge-in, the RECOGNIZE command would not start the timers. Sending this command will start the No Input Timer.
Resource headers
It is highly recommended that you set your own values using command SET-PARAMS. We might change default values without notice, and they should be considered as a backup.
Logging-Tag
Supported by SET-PARAMS (and GET-PARAMS) only. This header sets a string value (at your convenience) that will be used to tag all the following interactions so you can easily track them in the development console.
Confidence-Threshold
A float between 0 and 1. Default value: 0.5.
ASR and interpretation determine a confidence value for the provided result. Value can be changed for your session depending on your needs. Raising the value closer to 1 might be useful in order to increase your certainty in the result, as it might sometimes happen that noise will disturb ASR and therefore the grammar's result.
If output confidence value is below this threshold, a no-match will be returned.
No-Input-Timeout

RECOGNIZE command if start-input-timer header is true, or after a START-INPUT-TIMER command if the same header is false. In the end, no voice has been detectedIn milliseconds, an integer greater than or equal to 0. Default value: 5300.
When recognition is started and there is no speech detected for a certain period of time, the recognizer can send a Recognition Complete event to the client with a Completion-Cause of "no-input-timeout" and terminate the recognition operation.
This header allows client to set this timeout.
Recognition-Timeout

In milliseconds, an integer greater than or equal to 0. Default value: 30000.
When recognition is started and there is no match for a certain period of time, the recognizer can send a Recognition Complete event to the client and terminate the recognition operation.
This header allows client to set this timeout.
This timeout is useful in order not to keep recognition going in case end-user is talking aside, or telling things outside the expected scope of the use case. In hotword mode, this timer is started anew each time the user will start to talk again after a silence. In normal mode it is started the first time the user speaks.
Start-Input-Timers
Boolean. Default value: false.
With this header set to false, recognition can be started, without starting the no-input timer yet. A Start-Input-Timers request is needed to start these timers then.
This header together with the Start-Input-Timer command is useful to implement barge-in.
Speech-Complete-Timeout

In milliseconds, an integer greater than or equal to 0. Default value: 1000.
The length of silence required following user speech before the recognizer finalizes a result. This value applies when the result is a complete match against an active grammar.
If the result ends up being incomplete, Speech-Incomplete-Timeout will apply.
Speech-Incomplete-Timeout

In milliseconds, an integer greater than or equal to 0. Default value: 2000.
The length of silence required following user speech before the recognizer finalizes a result. This value applies when the result is a partial match against all active grammars.
If the result ends up being complete, Speech-Complete-Timeout will apply.
For more details, please check RFC-6787.
Make sure this parameter's value is greater than Speech-Complete-Timeout's one.
Content-Type
A string. As we only support builtin grammars, its value must always be text/uri-list
The list of grammars is then passed into the body.
Only applies to commands DEFINE-GRAMMAR and RECOGNIZE.
Content-ID
A String.
Set an ID for the defined grammar, with which it can be referenced for the duration of the session.
For example, a grammar can be defined with the ID account_number using a spelling digits builtin of length 8, because for the IVR's scenario, we're asking user for its account/contract number. The Content ID will then be available for the duration of the session under session: namespace, that is session:account_number.
Only applies to command DEFINE-GRAMMAR.
Sensitivity-Level
A float between 0 and 1. Default value: 0.5.
Used to set the separation threshold between the main voice and the secondary interfering voice. We highly recommended to keep the default value for a first attempt, as we have benchmarked this value against our test corpus.
In case of a second attempt (following a no-match or no-input), and only then, do we recommend changing its value.
Following a no-input, meaning that no voice has been detected, value can be raised, for example to 0.75. No-input can mean that user's voice volume is low, or maybe that nothing has been said indeed.
Following an abnormally early no-match returning a transcript nonetheless (especially when implementing barge-in), then maybe user's environment is noisy, and a second try with a lower value (for example 0.3) might give better results.
Setting a fixed value, different from the default one, for a whole scenario does not make sense and should not be done. This parameter should always be set dynamically, and with caution.
N-Best-List-Length
An integer between 1 and 5. Default is 1.
When the recognizer matches an incoming stream with the grammar, it may come up with more than one alternative match because of confidence levels in certain words or conversation paths. If this header field is not specified, by default, the recognizer resource returns only the best match above the confidence threshold. The client, by setting this header field, can ask the recognition resource to send it more than one alternative. All alternatives must still be above the Confidence-Threshold. A value greater than one does not guarantee that the recognizer will provide the requested number of alternatives. This header field MAY occur in RECOGNIZE, SET-PARAMS, or GET-PARAMS. The minimum value for this header field is 1. The default value for this header field is 1.
Speech-Language
A String following RFC 5646.
Defines the language to be used for transcription.
For the moment we support:
de, Germanen,en-US,en-UK, Englishes, Spanishfr, French- Some business domain extensions, such as banking, telecom, insurance, travel... Reach out to your account manager for more information.
- Custom language models built with our LM Factory, that best meet your needs and use cases. Reach out to your account manager for more information.
When requesting a specific Speech-Language in your request, it might not end up being the Language Model used to transcribe the audio, depending on permission and requested builtin. For example requesting your own fr-fr-x-acme model together with the Postal Address builtin will force the use of a dedicated and more efficient address-oriented Language Model. Response payload will contain information regarding the Language Model that was effectively used. You can also see details about that on the H2B Developer Console.
Hotword-Min-Duration
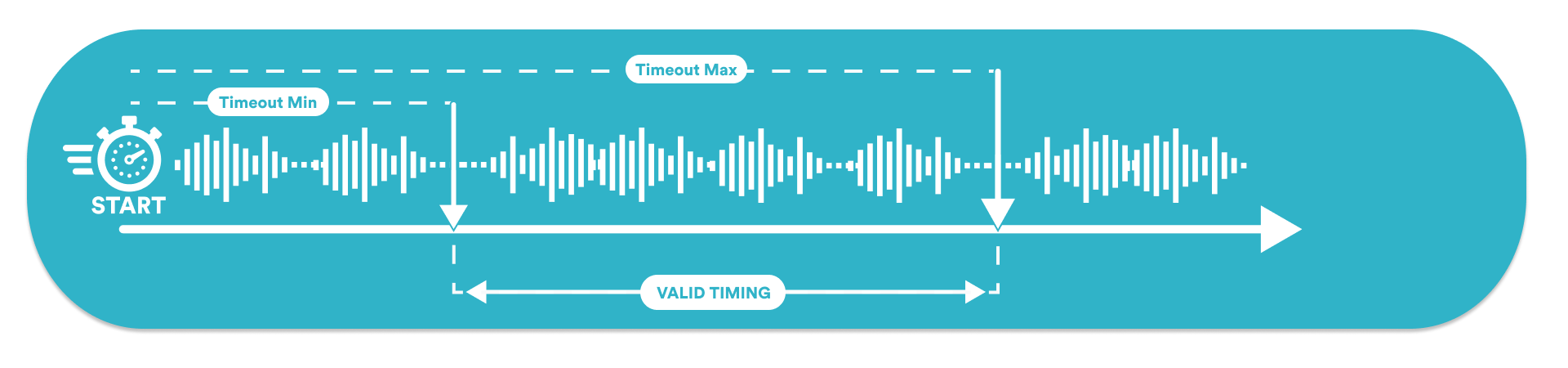
In milliseconds, an integer above 0. Default is undefined.
The minimum duration of an utterance that will be considered for hotword recognition.
For example, if you're expecting the user to give their phone number as a spelling of digits, it is reasonable to expect them to take more than one or two seconds to do so. By setting this duration, result interpretation can be tuned for better performances.
Only valid for commands RECOGNIZE and SET-PARAMS. It will only apply for hotword mode.
Hotword-Max-Duration
In milliseconds, an integer above 0. Default is undefined.
The maximum duration of an utterance that will be considered for hotword recognition. The timer starts when the speech recognition starts.
For example, if you're expecting the user to give a keyword after offering them 3 different choices, it is reasonable to expect them to take less than five or six seconds to do so. By setting this duration, result interpretation can be tuned for better performances.
Only valid for commands RECOGNIZE and SET-PARAMS. It will only apply for hotword mode.
Recognition-Mode
String, either normal or hotword. Default is normal.
Only valid for command RECOGNIZE.
More information about both normal mode and hotword mode can be found below.
Extended resource headers
We provide some extended parameters that can be specified in the Vendor-Specific-Parameters MRCPv2 header.
Speech-Nomatch-Timeout

In milliseconds, an integer above 0. No default value. This parameter must be explicitly set.
There was a bug prior to version 1.26.0 when the function was activated with a default value of 3000.
This parameter specifies the required length of silence after speech to declare end-of-speech in case none of the grammars matched what the user said.
Make sure this parameter's value is greater than Speech-Incomplete-Timeout's one.
Recognize Modes
Two recognition modes are proposed: normal mode and hotword. They differ mainly on how they match grammars and how they terminate. When a client issue a RECOGNIZE request, it must specify the recognition mode.
Normal mode
This is a free mode. Once a speech segment is detected, the ASR starts. It will begin to transcribe what was said by the caller and then analyze the content. The ASR will automatically stop after a speech utterance followed by silence of a given duration, or after a timeout if that parameter has been set (see header speech-complete-timeout, header speech-incomplete-timeout and the vendor-specifc header speech-nomatch-timeout, depending on the interpretation state).
There is 3 types of possible results in that mode:
- Complete match: if the transcribed content match exactly what was expected.
- Partial match: if the content only partially matches what was expected (example: a zip code is expected, but only 3 digits were spoken).
- No-match: This can have several explanations:
- The caller’s answer does not fit into the expected grammar used
- If the recognition timeout has been reached without the caller having been able to express themselves
Hotword mode
This mode can only be used with "closed" grammars.
In this mode, we no longer wait for a given duration or simply for the caller to stop speaking in order to stop the ASR. When the caller speaks, if the ASR transcribes and completes the associated grammar (so as soon as a complete match is obtained), then it will stop immediately. This has several advantages:
- Allowing more time for the caller to express themselves, if they need to, without stopping the ASR at each breath segment (example: a client starts to speak then pauses)
- Improve the fluency of the dialogue by allowing the ASR to be automatically stopped once the grammar has been completed.
However, in this mode, there is no partial match possible, only the two following results:
- If the caller has completed the grammar: complete match
- If the caller has not completed the grammar or just partially within
recognition-timeoutorhotword-max-duration: no-match (example: a zip code is expected, only 3 digits were spoken = no-match).
In order not to disturb the good progress of the scenario, there are also two usable parameters:
Hotword-Max-Duration: maximum duration of the ASR, see documentation. A result will be returned even if the caller is still talking after this time.Hotword-Min-Duration: minimum duration of ASR, see documentation.
User Experience and best practices
Barge-in
Barge-in describe the fact of letting end-user talk over the bot. It's useful for example if users are expected to be able to tell their answer before the bot has finished talking. When the user's voice is detected, the bot is muted.
In order to propose barge-in:
- First, the command
RECOGNIZEis sent with headerStart-Input-TimerstoFalse. - User might start to talk or not. Depending on parameters, an output might even be returned while the bot is still talking.
- Once the bot has finished to talk, command
START-INPUT-TIMERShas to be sent in order to start NoInput timer. - User is either still talking, or starts now. We are now in a case similar to non barge-in.
Implementing barge-in means that recognition is started when the robot is still talking, so please be cautious regarding the following points, as it might deteriorate the User Experience:
- As a result, recognition might be running for quite a long time in case the end-user is waiting for the end of the robot's prompt. This means an increase in ASR costs (up to 3 times compared to the same interaction without barge-in would not be a surprise).
- If end-user use their phone on loudspeakers, recognition might catch the bot talking, and therefore disturb results.
- If the barge-in is total, that is, if the recognition is started at the same time that the robot starts talking, the robot may be muted before talking, in the case the user is already speaking. So it's better to delay the recognition start a few seconds after the bot has started talking.
Most users are not aware that the bot is listening while talking, so they may engage in other activities (including chatting, listening to the TV, Radio…) during this time and trigger the barge-in, callers from busy places may also be unable to use your service because of it. In the end, this could cause frustration to your user, and we recommend you to implement this feature into your SVI with care. In any case, you should inform them early about this feature if you implement it.
See also the troubleshooting page.